Artificial Intelligence for Medical Imaging
We develop new AI methods to enhance image acquisition and reconstruction, automate image analysis and processing, and enable fully automated computer-assisted disease diagnosis and prediction.
A full list of our publications in this category can be found here.
Research Highlight
AI and Machine Learning for Rapid MRI
In recent years, AI and machine learning have shown promise in enhancing the quality of images generated from undersampled MRI data, presenting new possibilities for improving rapid MRI performance. Unlike traditional rapid imaging methods, machine learning-based approaches redefine image reconstruction as a process of learning features by analyzing undersampled image structures from a vast image database. These data-driven techniques have effectively eliminated artifacts from undersampled images, converted k-space information into images, predicted missing k-space data, and reconstructed MR parameter maps. We have developed a novel method to advance AI-based image reconstruction by reimagining the key components of reconstruction efficiency, accuracy, and robustness. This new framework, called Sampling-Augmented Neural Network with Incoherent Structure (SANTIS), employs a unique combination of data cycle-consistent adversarial network, efficient end-to-end convolutional neural network mapping, data fidelity enforcement, and adversarial training to reconstruct undersampled MR images.
SANTIS was evaluated for reconstructing undersampled knee images using a Cartesian k-space sampling scheme and undersampled liver images using a non-repeating golden-angle radial sampling scheme. SANTIS showed superior reconstruction performance in both datasets and significantly improved robustness and efficiency compared to several reference methods.
Presentation in ISMRM 27th Annual Meeting Educational Session

AI for Accelerated and Improved Quantitative MRI
Our team has developed a new AI framework to speed up MR parameter mapping. We have proven that the AI framework is effective, efficient, and reliable in addressing the challenges of conducting fast quantitative MR imaging. Among various MR techniques, quantitative mapping of MR parameters has always been a valuable tool for better evaluation of different diseases. Unlike traditional MRI, parameter mapping can offer greater sensitivity to tissue abnormalities and more specific information about tissue composition and microstructure. However, standard methods for estimating MR parameters typically involve obtaining multiple sets of data with different imaging parameters, leading to long scan times. Therefore, there is a strong interest in accelerated methods within the MR community.
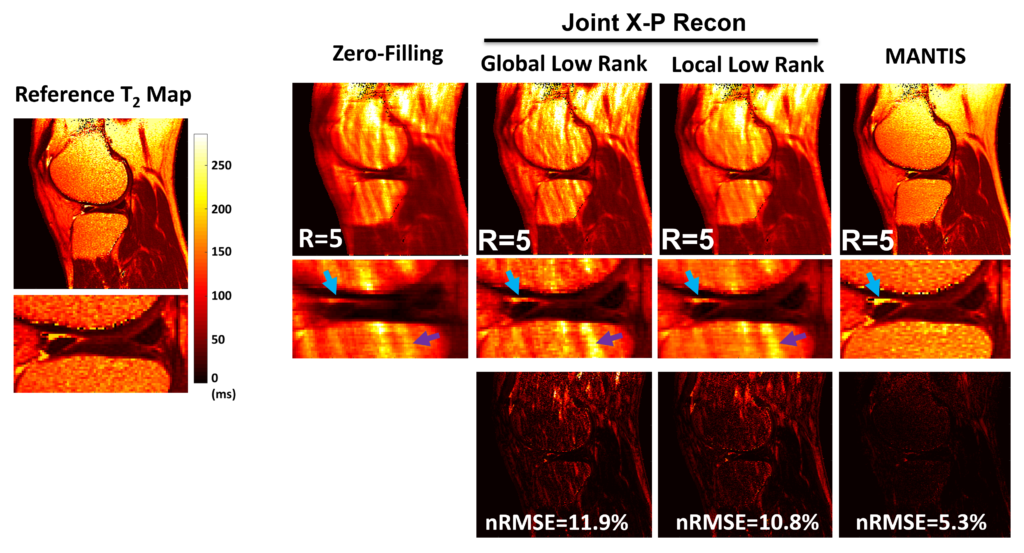
We have developed a method called MANTIS, which stands for Model‐Augmented Neural neTwork with Incoherent k‐space Sampling, to reconstruct MR parameter maps using less data. The MANTIS algorithm combines a convolutional neural network mapping, model augmentation for data consistency, and incoherent k‐space undersampling. The convolutional neural network converts undersampled images directly into MR parameter maps, which allows for efficient cross-domain transform learning. To ensure fidelity to the signal model, a pathway is established between the undersampled k‐space and estimated parameter maps to guarantee that the algorithm constructs accurate parameter maps consistent with the acquired k-space measurements. Additionally, a randomized k-space undersampling strategy is employed to create incoherent sampling patterns that are suitable for the reconstruction network and capable of capturing robust image features.
Our study showed that the MANTIS framework is a promising approach for quickly mapping T2 in knee imaging, with up to 8-fold acceleration. In future research, MANTIS could be expanded to include other types of parameter mapping, like T1 imaging, T1ρ imaging, diffusion, and perfusion, using suitable models and training data sets.
Presentation in 2018 ISMRM Workshop on Machine Learning Part II

- Liu F, Feng L, Kijowski R: MANTIS: Model-Augmented Neural neTwork with Incoherent k-space Sampling for efficient MR T2 mapping. Magn Reson Med. 2019; 82 (1), 174-188.
- Liu F, Kijowski R, Feng L, El Fakhri G: High-performance rapid MR parameter mapping using model-based deep adversarial learning. Magnetic Resonance Imaging. 2020; 74, 152-160.
Unsupervised and Self-supervised Deep Learning for MRI Reconstruction
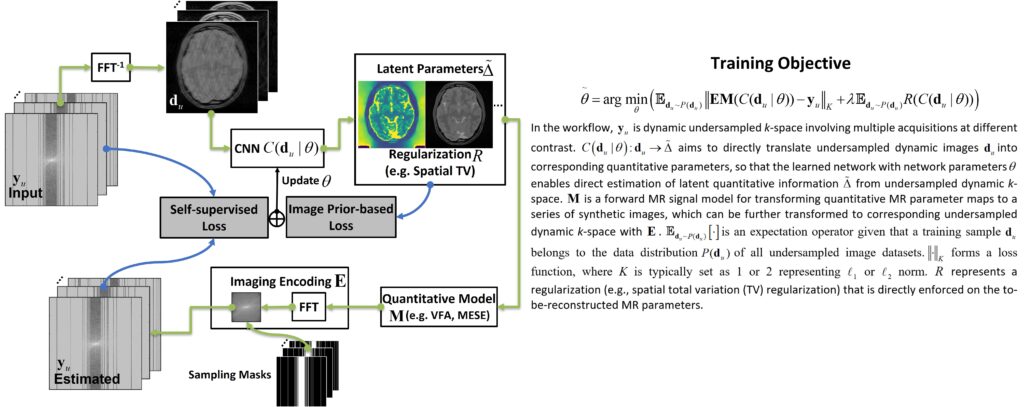
Deep learning methods have shown promise in image reconstruction, particularly in MRI. However, most current deep learning-based MRI reconstruction techniques rely on supervised training, which requires a large number of high-quality reference images. Acquiring such reference images can be challenging, especially for quantitative MRI, which typically involves long imaging times and is not commonly used in clinical settings. To address this limitation, we propose a self-supervised deep learning reconstruction framework for quantitative MRI, called REference-free LAtent map eXtraction (RELAX). This technique combines data-driven and physics-driven training to enable self-supervised deep learning reconstruction for quantitative MRI.
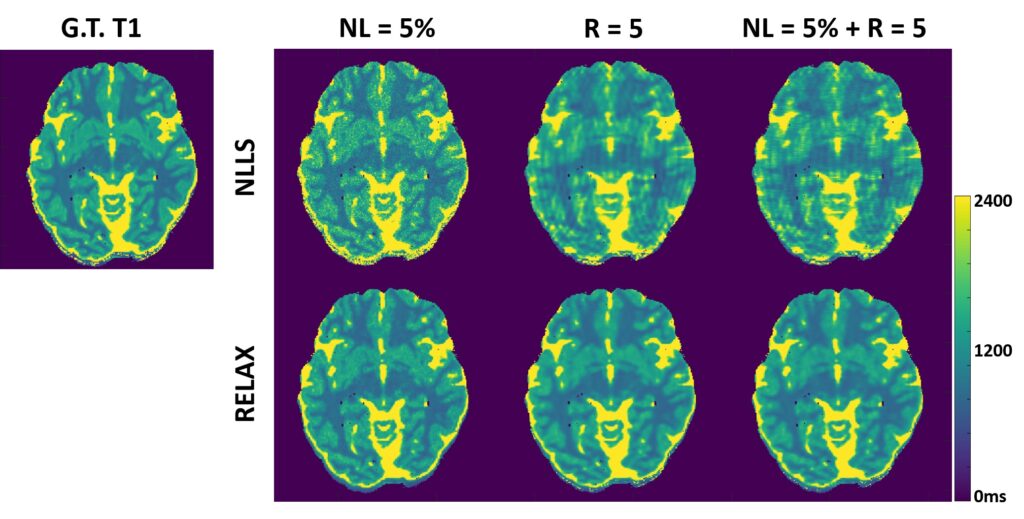
Two physical models are utilized for network training in RELAX. These models include the inherent MR imaging model and a quantitative model used to fit parameters in quantitative MRI. By imposing these physical model constraints, RELAX eliminates the requirement for full sampled reference datasets needed in standard supervised learning. Additionally, RELAX allows for direct reconstruction of corresponding MR parameter maps from undersampled k-space. To enhance the reconstruction quality, the RELAX framework can also incorporate generic sparsity constraints commonly used in conventional iterative reconstruction, such as the total variation constraint. The performance of RELAX was evaluated for accelerated T1 and T2 mapping using both simulated and acquired MRI datasets. It was compared with supervised learning and conventional constrained reconstruction to assess its ability to suppress noise and/or undersampling-induced artifacts.
Our study has demonstrated the initial feasibility of rapid quantitative MR parameter mapping based on self-supervised deep learning. The RELAX framework may be further extended to other quantitative MRI applications by incorporating corresponding quantitative imaging models.
- Liu F, Kijowski R, El Fakhri G, Feng L: Magnetic resonance parameter mapping using model-guided self-supervised deep learning. Magn Reson Med. 2021; 85 (6), 3211-3226.
- Bian W, Jang A, Liu F: Improving quantitative MRI using self‐supervised deep learning with model reinforcement: Demonstration for rapid T1 mapping. Magn Reson Med. 2024; doi:10.1002/mrm.30045.
Learning Optimal Image Acquisition and Reconstruction
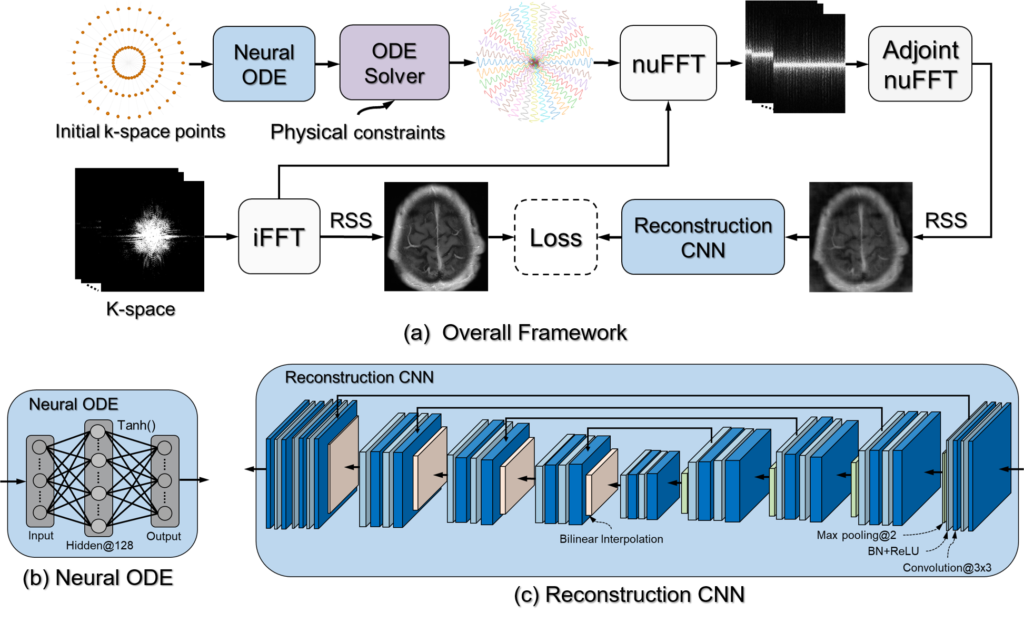
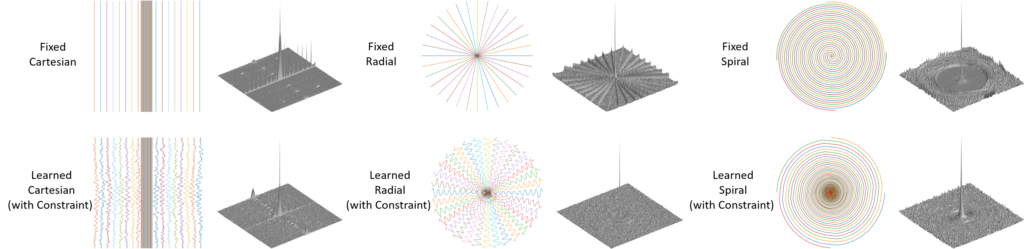
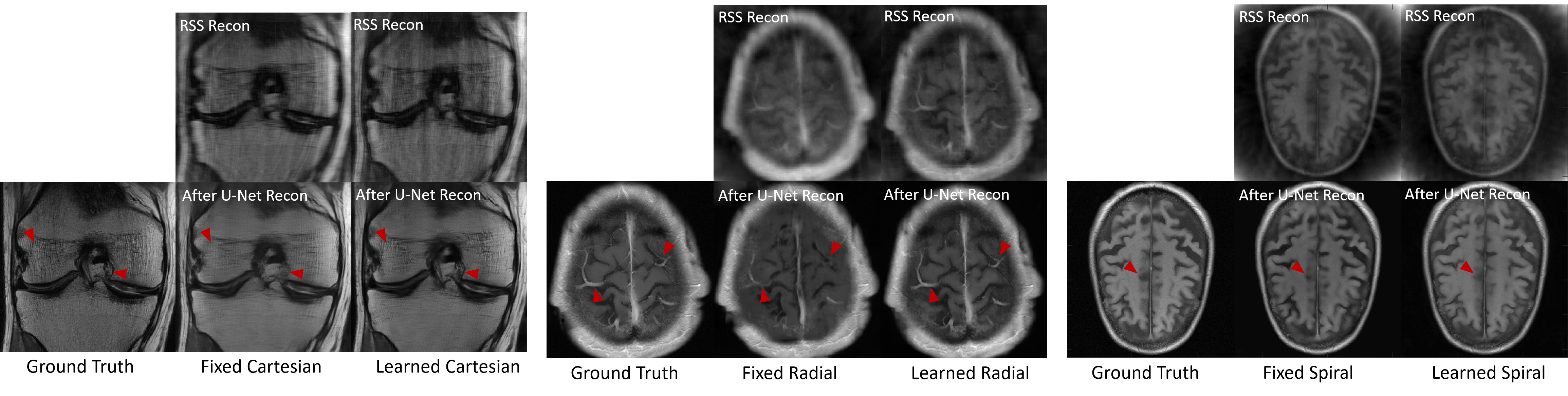
The slow imaging speed of MRI has led to the development of various acceleration methods, often involving undersampling the MRI measurement domain known as k-space. Recently, deep neural networks have been used to reconstruct undersampled k-space data and have demonstrated improved reconstruction performance. While existing methods focus on designing reconstruction networks or training strategies for specific undersampling patterns, such as Cartesian or Non-Cartesian sampling, there is limited research on using deep neural networks to learn and optimize k-space sampling strategies. We have developed a novel optimization framework to learn k-space sampling trajectories by treating it as an Ordinary Differential Equation (ODE) problem solvable using neural ODE. The sampling of k-space data is framed as a dynamic system, and neural ODE is used to approximate the system with additional constraints on MRI physics. Furthermore, we have shown that trajectory optimization and image reconstruction can be learned collaboratively to improve imaging efficiency and reconstruction performance. We conducted experiments on various in-vivo datasets, including brain and knee images acquired with different sequences.
In our study, we introduced a new deep learning framework for learning MRI k-space trajectory optimization. Our method consistently outperforms the regular fixed k-space sampling strategy. It is efficient and adaptable for various Cartesian and Non-Cartesian trajectories across different image sequences, contrasts, and anatomies. Our approach offers a new opportunity to improve rapid MRI by ensuring optimal acquisition while maintaining high-quality image reconstruction.
Multi-modality Image Synthesis and Applications
We have created a set of unique AI algorithms to generate and synthesize images across different modalities. Our techniques can be used to convert image contrasts between MRI, CT, and PET scans. Our research group is one of the first to explore AI-based multi-modality imaging studies, and we have tested our methods in various clinical applications such as PET/MRI attenuation correction, motion correction, and MRI-guided radiation therapy.
Deep Learning MR-based Attenuation Correction (deepMRAC) for PET/MR
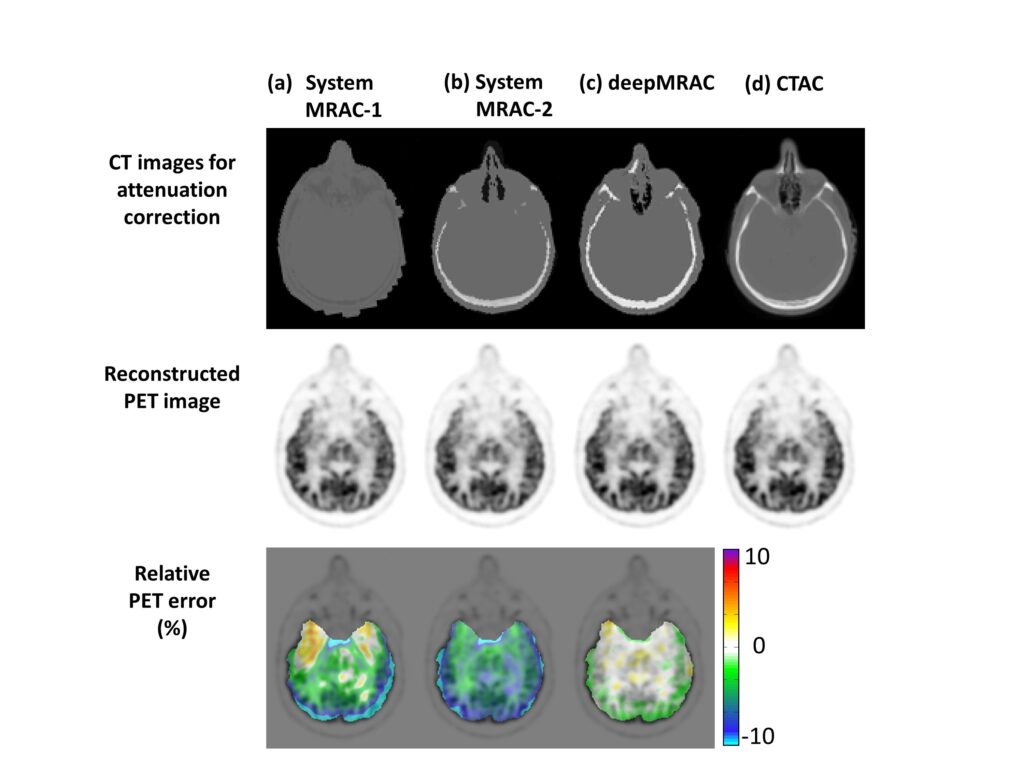
A PET/MR attenuation correction pipeline was created using a deep learning method to produce pseudo-CTs from MR images. A deep convolutional auto-encoder network was trained to recognize air, bone, and soft tissue in 3D head MR images aligned with CT data for training. This automated method enabled the creation of a specific pseudo-CT (soft tissue, bone, and air) from a single high-resolution 3D MR image of diagnostic quality and was tested in PET/MR brain imaging.
Utilizing a single MR acquisition, deepMRAC performs better than current clinical approaches. The reconstruction error for deepMRAC is -0.7±1.1%, while it is -5.8±3.1% and -4.8±2.2% for soft tissue only and atlas-based approaches, respectively. The application of deep learning-based approaches to MR-based attenuation correction has the potential to generate robust and reliable quantitative PET/MR imaging and could have a significant impact on future work in quantitative PET/MR.
- Liu F, Jang H, Bradshaw T, Kijowski R, McMillan A: Deep Learning MR Imaging-based Attenuation Correction for PET/MR Imaging. Radiology. 2017; 286 (2), 676-684.
- Jang H, Liu F, Zhao G, Bradshaw T, McMillan A: Deep Learning Based MRAC Using Rapid Ultra-short Echo Time Imaging. Med Phys. 2018; 45 (8), 3697-3704.
- Bradshaw T, Zhao G, Jang H, Liu F, McMillan A: Feasibility of Deep Learning-Based PET/MR Attenuation Correction in the Pelvis Using Only Diagnostic MR Images. 2018; Tomography. 5(1):24.
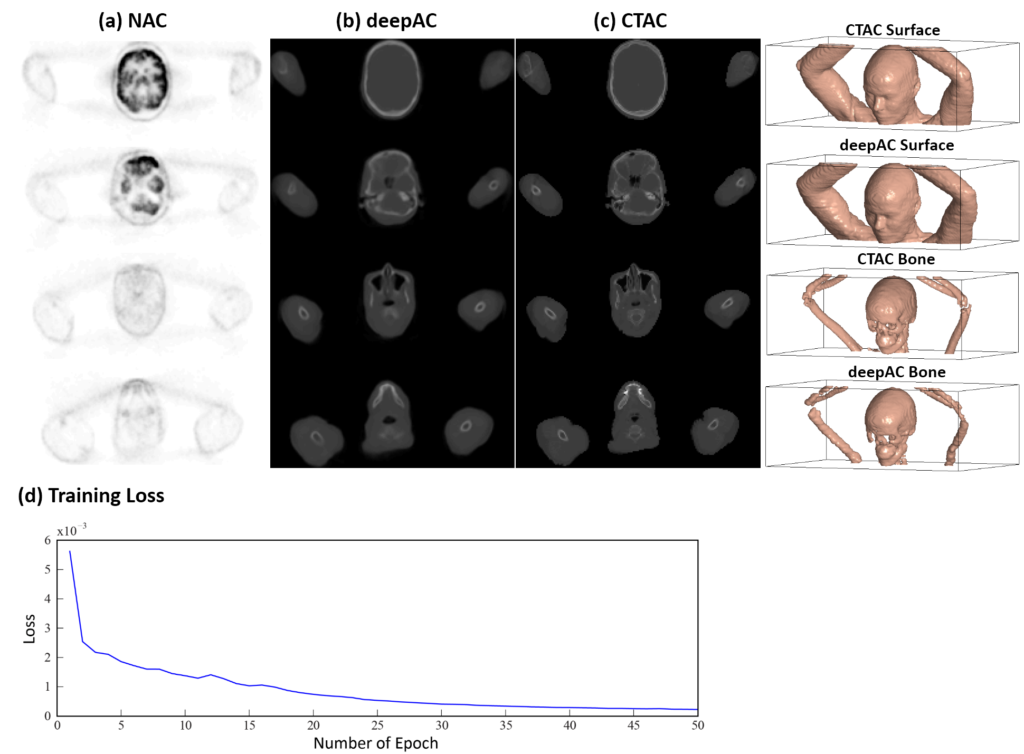
Self-regularized Deep Learning-based Attenuation Correction (deepAC) for PET
We have developed an automated approach (deepAC) that enables the generation of a continuously valued pseudo-CT from a single 18F-FDG non-attenuation-corrected (NAC) PET image. We have evaluated this approach in PET/CT brain imaging.
A data-driven deep learning approach (deepAC) for PET image attenuation correction without anatomical imaging was developed and evaluated for feasibility. The approach involved using deep learning to create pseudo-CT images from uncorrected 18F-fluorodeoxyglucose (18F-FDG) PET images. A deep convolutional encoder-decoder network was trained to identify tissue contrast in volumetric uncorrected PET images that were co-registered to CT data. The model was trained using a set of 100 retrospective 3D FDG PET head images and evaluated in 28 patients. The evaluation involved comparing the generated pseudo-CT to the acquired CT using Dice coefficient and mean absolute error, as well as comparing reconstructed PET images using the pseudo-CT and acquired CT for attenuation correction.
deepAC has been discovered to generate precise quantitative PET imaging using only NAC 18F-FDG PET images. These methods are expected to significantly influence future research in PET, PET/CT, and PET/MR studies by reducing ionizing radiation dose and improving the ability to handle misalignment between the PET acquisition and the attenuation map acquisition.
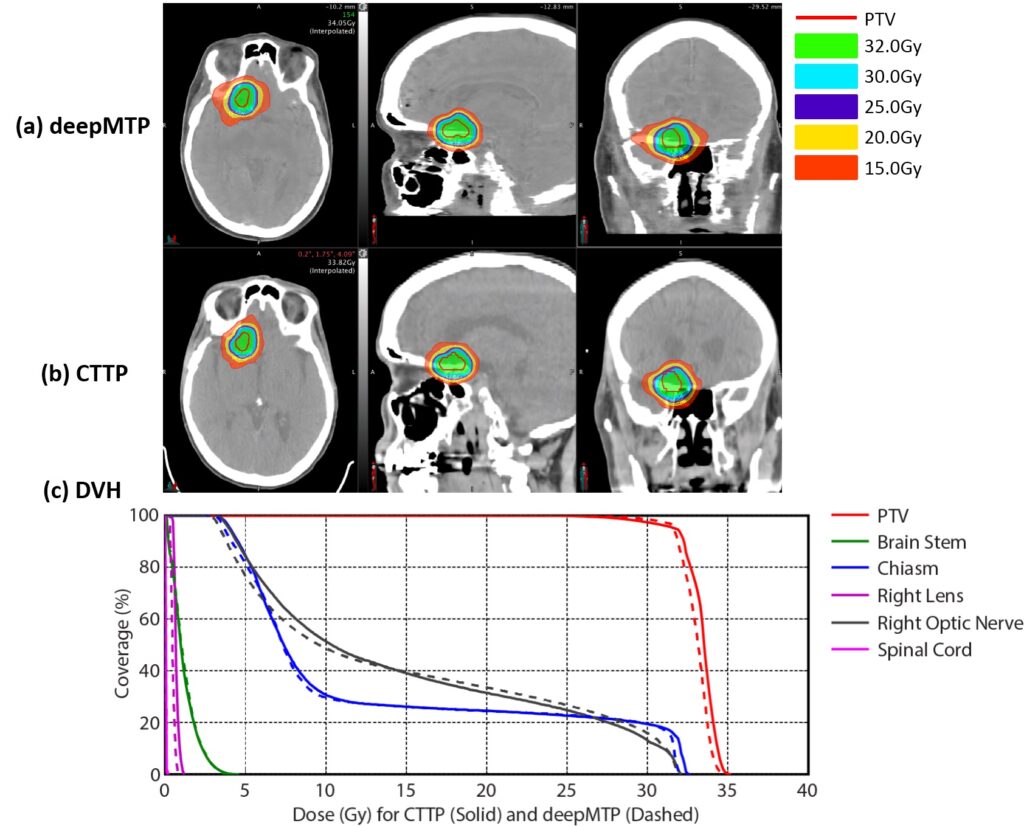
Deep Learning-based MRI-guided Radiation Therapy Treatment Planning
One of the main challenges in MRI-based treatment planning is the difficulty in obtaining electron density for dose calculation. Unlike conventional CT-based treatment planning, where additional CT images can be adjusted to create a photon attenuation map (μ-map), MRI does not provide linear image contrast and has limitations in producing clear contrast in bone, which is the most attenuating tissue. As a result, there is no simple way to convert MR images to a μ-map for accurate dose calculation. Additionally, other challenges include MR image artifacts due to the complex image formulation and potentially longer scan times compared to CT scans.
We have created a method called deepMTP, which can produce a detailed pseudo-CT from a single high-resolution 3D MR image. We tested this method in planning treatment for partial brain tumors and found that the dose distribution it provided was not significantly different from that of a standard volumetric modulated arc therapy plan based on kVCT (CTTP).
We have found that using deep learning techniques for MR-based treatment planning in radiation therapy can produce treatment plans that are comparable to those produced using CT-based methods. Further development and clinical evaluation of these approaches for MR-based treatment planning could provide more accurate dose coverage and reduce treatment-related dose in radiation therapy. This could improve the workflow for MR-only treatment planning, taking advantage of the improved soft tissue contrast and resolution of MR. Our study shows that deep learning techniques, such as deepMTP, will have a significant impact on future work in treatment planning for the brain and other parts of the body.
AI-empowered Disease Diagnosis and Prediction
We are at the forefront of using AI to enhance disease diagnosis and prevention. Our team has developed several AI systems and frameworks aimed at advancing current medical practices. Specifically, we have created fully-automated AI systems for detecting lesions and tears in knee cartilage and cruciate ligaments using 3D multi-contrast MRI data, predicting disease progression in knee osteoarthritis based on X-ray data, and rapidly diagnosing COVID-19 using 3D CT image datasets combined with demographic information.
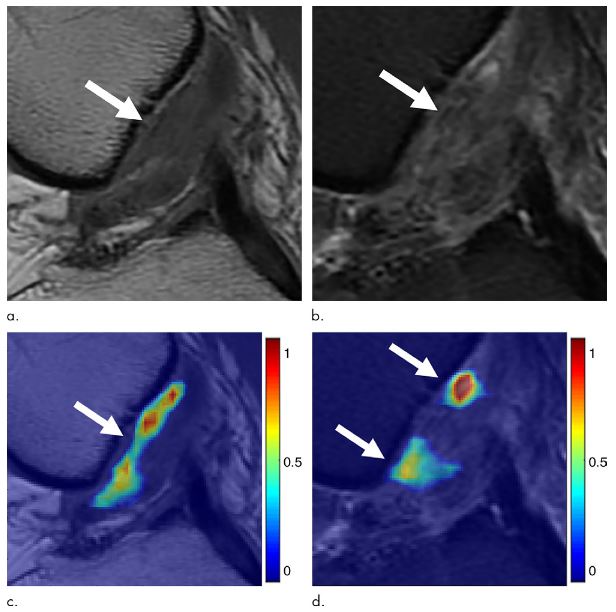
A Deep Learning Framework for Detecting Cartilage Lesions on Knee MRI
Identifying cartilage lesions, such as cartilage softening, fibrillation, fissuring, focal defects, diffuse thinning due to cartilage degeneration, and acute cartilage injury, in patients undergoing MRI of the knee joint, has many important clinical implications.
We have shown that it is possible to use a fully automated deep learning-based system to detect cartilage lesions in the knee joint. The system has demonstrated high diagnostic performance and good intraobserver agreement in detecting both cartilage degeneration and acute cartilage injury.
A cartilage lesion detection system was developed using fully automated deep learning algorithms, which involved segmentation and classification convolutional neural networks. The system analyzed fat-suppressed T2-weighted fast spin-echo MRI data sets of the knee retrospectively. Diagnostic performance and intraobserver agreement for detecting cartilage lesions were assessed using receiver operating curve analysis and the κ statistic for two individual evaluations performed by the system.

Detecting Cruciate Ligament Tears using Multi-scale Cascaded Deep Learning
Anterior cruciate ligament (ACL) tears are a common injury in sports. Detecting an ACL tear involves evaluating an obliquely oriented structure on multiple image sections with different tissue contrasts using MRI findings. These findings include fiber discontinuity, changes in contour, and signal abnormality within the injured ligament. It would be helpful to investigate whether a deep learning approach can aid in the diagnosis of complex musculoskeletal abnormalities on MRI.
We have created a fully automated system for identifying an ACL tear using two deep convolutional neural networks to pinpoint the ACL on MR images. We then use a classification CNN to detect any structural abnormalities within the isolated ligament. This study aimed to explore the possibility of using a deep learning approach to identify a full-thickness ACL tear in the knee joint on MRI, with arthroscopy serving as the reference standard.
Our system can detect ACL tears with similar accuracy to clinical radiologists using specific MRI images. However, an AI system significantly improves detection efficiency and robustness.

Prediction of Knee Osteoarthritis Progression using Deep Learning on X-ray Images
Osteoarthritis (OA) is a highly common and disabling chronic disease in the United States and around the world. The knee is the joint most frequently affected by OA. Identifying individuals at high risk for knee OA incidence and progression would offer an opportunity to modify the disease during its earliest stages. This is when interventions such as weight loss, physical activity, and range of motion and strengthening exercises are likely to be most effective.
It’s crucial to develop OA risk assessment models for widespread use in clinical practice. However, current models, which mainly rely on clinical and radiographic risk factors, have only had moderate success in predicting the occurrence and progression of knee OA. Including semi-quantitative and quantitative measures of knee joint pathology from baseline X-rays and MRI scans has improved the diagnostic accuracy of OA risk assessment models. However, the time and expertise required to obtain these imaging parameters would make it difficult to incorporate them into cost-effective, widespread OA risk assessment models.
We created and assessed fully automated deep learning risk assessment models to predict the advancement of radiographic knee OA using initial knee X-rays. Our findings indicate that the deep learning models exhibited better diagnostic performance in predicting the progression of radiographic knee OA compared to traditional models that utilized demographic and radiographic risk factors.


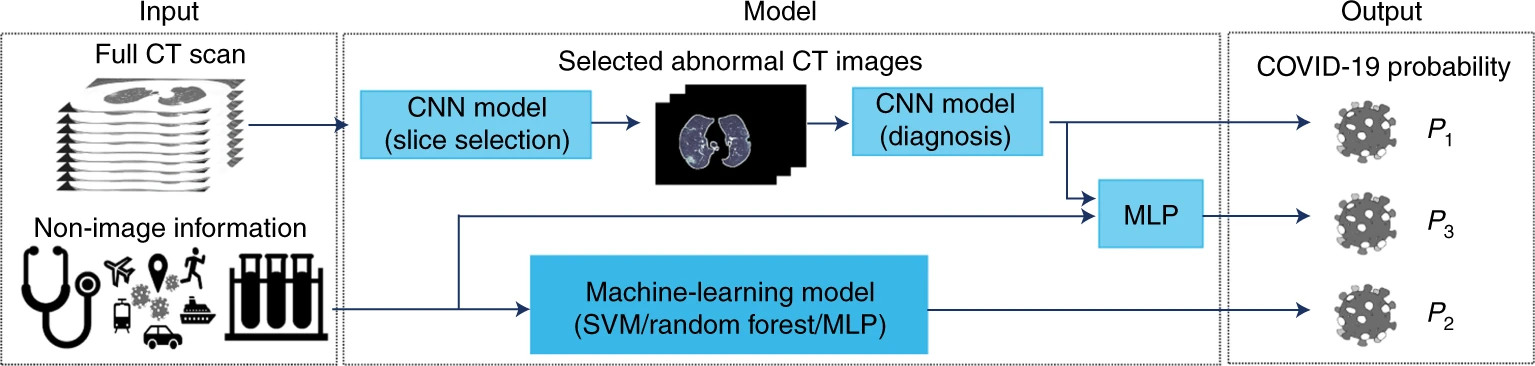
A Deep Learning Framework for Predicting COVID-19 on Chest CT
To diagnose COVID-19, the SARS-CoV-2 virus-specific RT-PCR test is typically used. However, this test can take up to 2 days to complete and may require multiple tests to rule out false negative results. There is also currently a shortage of test kits, highlighting the urgent need for alternative rapid and accurate diagnostic methods for COVID-19. While chest CT scans are helpful in evaluating patients with suspected SARS-CoV-2 infection, they alone may not always accurately rule out the infection, especially in the early stages when some patients may have normal radiological findings.
In a study published in early 2020, AI algorithms were used to combine chest CT findings with clinical symptoms, exposure history, and laboratory testing for the rapid diagnosis of COVID-19 positive patients. The AI system achieved an area under the curve of 0.92 and showed equal sensitivity compared to a senior thoracic radiologist. Additionally, the AI system improved the detection of patients who tested positive for COVID-19 via RT–PCR but had normal CT scans, while radiologists misclassified all these patients as COVID-19 negative. When CT scans and relevant clinical history are available, this proposed AI system can be valuable in the rapid diagnosis of COVID-19 patients.